
pagode: enriching digital heritage collections
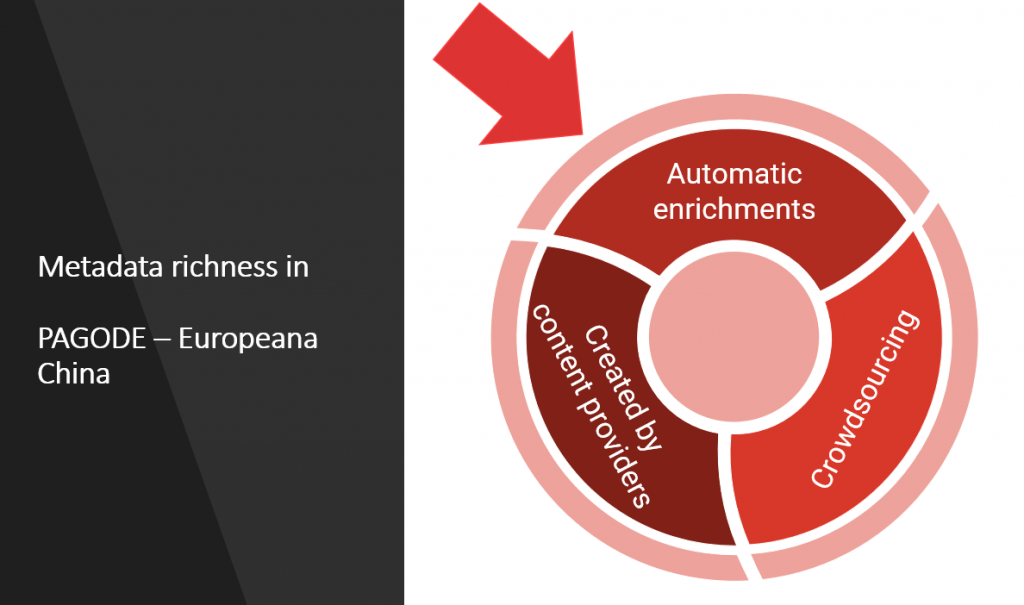
Next to creating new and high-quality cultural heritage records from digitization, among the activities in PAGODE a big effort was deployed to annotate and enrich with additional concepts (i.e. metadata) a selection of existing collections from Europeana, thus adding more and richer information for a better use experience in Europeana. This work was done in two different actions:
- Deep curatorial annotation on selected objects: this is also called the PAGODE Annotation Pilot, and the action made use of a crowdsourcing platform, where users can access curated collections sourced from Europeana and manually “tag” each record with appropriate keywords about places, subjects and highly-specific terms related to Chinese heritage. This task was coordinated by partner Photoconsortium and was also presented in a dedicated seminar during the PAGODE Digital Festival.
- Automated semantic enrichment: by the use of algorithms and artificial intelligence, additional metadata are extracted from the existing records. The additional metadata are then re-associated to the cultural resource, also adding links to authority files and established LOD thesauri. A human-in-the-loop approach in the validation of the enrichments guarantees the highest level of confidence for these AI-generated information, thus sending back to Europeana trustable metadata. This task was coordinated by partner PostScriptum.
Both actions were based on specific lists of keywords about Chinese heritage, developed by the Sinologists specialized in Chinese heritage semantics of the University of Ljubljana.
a complex work for improving metadata
One target of PAGODE project was specifically dedicated to automatic enrichment of the metadata of a minimum of 20,000 records already present on Europeana, from various content partners. The process run through a number of phases:
Content selection: identification of datasets already published in Europeana which would benefit from metadata improvement/enrichment.
Identification of AI and NLP tools: automated enrichment by Artificial Intelligence (AI) and Natural Language Processing (NLP) techniques were applied to existing collections in Europeana. These two technologies allow to recognize automatically the information that is embedded in the content and in the metadata, and to add relevant terms and links to authority files in the existing metadata. This process had the advantage of enabling bulk enrichment of large datasets, which would require a huge effort and extended time scale if done manually.
Automatic enrichment: in the scope of PAGODE, automated enrichment was performed by use of algorithms trained with the list of keywords developed by the sinologists at the University of Ljubljana, and run on metadata sourced from existing Europeana collections. The algorithms recognize the terms and enrich the metadata with the links to the respective entries in Getty AAT or Wikidata, and the enrichments are made available to Europeana for display in the respective records. In order to create automatic semantic enrichments of EDM records we used the SAGE – Semantic Enrichment and Data management platform with an integrated validation subsystem. The SAGE platform, developed as open source independently from PAGODE, allows importing heterogeneous data (e.g. XML, CSV, JSON, RDF, etc.) from multiple sources and enriching the data through external services. Additionally, via this tool all the available multilingual translation from Wikidata and Getty links would be further available on the basis of Europeana mechanisms. The enrichments as automatically generated in PAGODE were forwarded to Europeana for publication via the Annotation API. The enrichments were provided in CSV files containing the Europeana item ID along with the respective URIs of the enrichments.
Validation: A human-in-the-loop approach in the validation of the enrichments guaranteed the highest level of confidence for this AI-generated information, thus sending back to Europeana trustable metadata. For this reason, a validation interface was integrated in the enrichment system and it was provided to the project partners to evaluate the produced annotations. The tool provided to the validators the option to accept/reject an annotation, or manually create new annotations where applicable. In terms of accuracy and trustworthiness of the validation process, a methodology and guidelines were given to the validators from the sinologists’ team of the University of Ljubljana, guaranteeing quality assurance and acting as a form of a strategy in order to reject low confidence annotations and filter out poor quality annotations. The validation process required that all datasets were 100% validated.
Ingestion to Europeana: The total amount of enriched records is 22,410, enriched with annotations using AAT or Wikidata. These enrichments were provided to Europeana via the Annotation API, to be then published in the Collections Portal.
image: PAGODE project
PAGODE – Europeana China is co-financed by the Connecting Europe Facility Programme of the European Union, under GA n. INEA/CEF/ICT/A2019/1931839






